
Continuando con las mediciones del rendimiento de nuestros servidores, llevaba tiempo para sacar un Post sobre cómo detectar problemas de latencia en discos, tanto FC, iSCSI como NFS, al menos desde que hice el curso para la obtención de la certificación VCP-410 y, hoy, al hilo de un artículo aparecido en el Blog de la Virtualización en Español, de nuestro gran maestro Jose María Gonzalez, retomo una de sus enseñanzas.
¿Cómo detectar problemas de latencia en disco de un ESXi? Dentro de nuestra herramienta de rendimiento, nos fijaremos en los siguientes contadores:
-
Kernel command latency.- tiempo medio empleado por el VMkernel para procesar un comando SCSI. Un número alto en este contador, (entre 2 a 3 milisegundos, puede significar:
- Que la cabina tenga un exceso de trabajo
- O que el servidor ESX/ESXi tenga un exceso de trabajo.
-
Physical device command latency.- Mide el tiempo medio que el dispositivo físico (disco) necesita para completar un comando SCSI. Un número alto en este contador (depende d la cabina, pero, en general, este valor está entre 15 y 20 milisegundos), puede significar dos cosas:
- O la cabina va muy lenta.
- O la cabina tiene un exceso de trabajo.
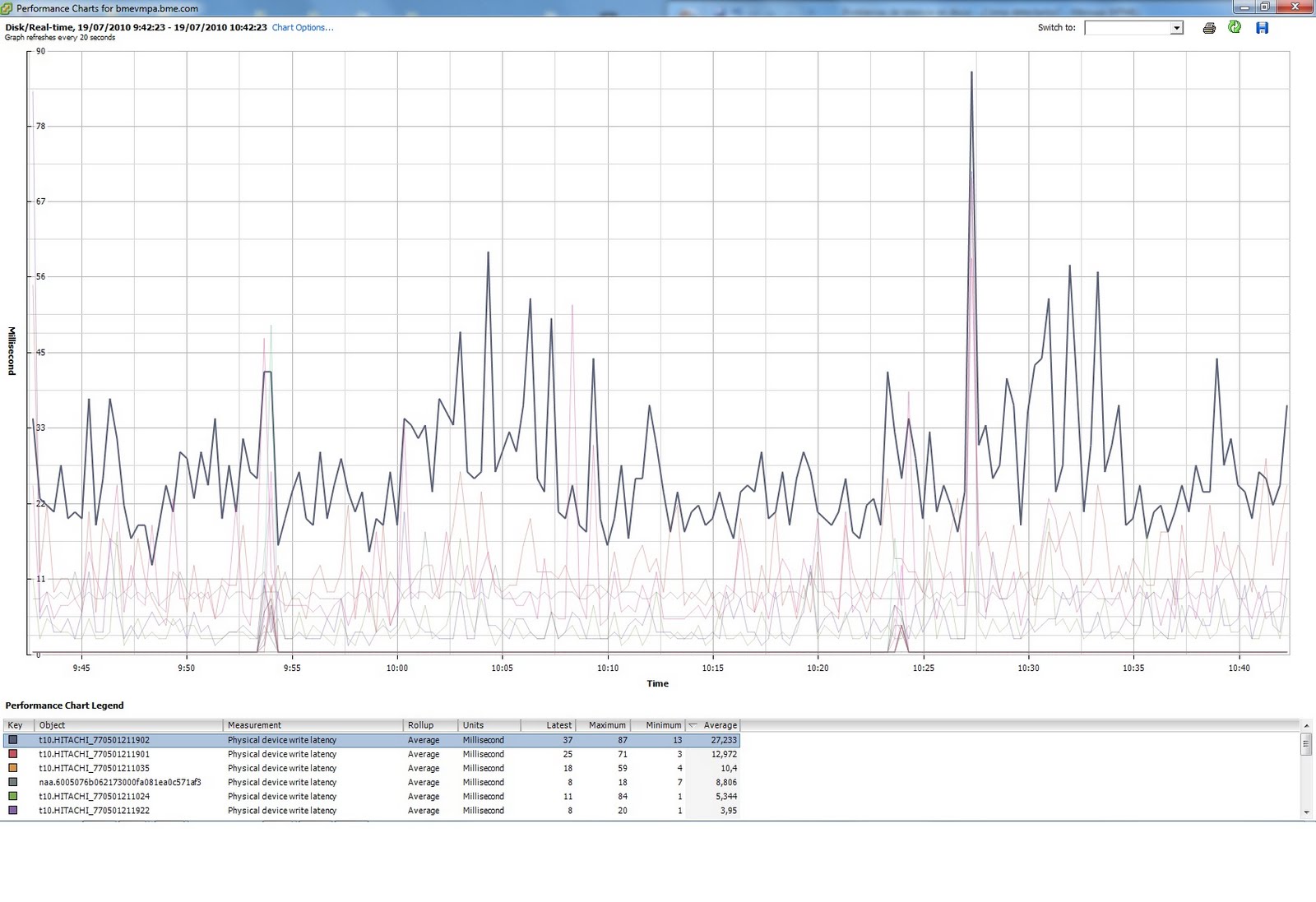
Vayamos a un ejemplo real. Configuro el primer contador (Kernel command latency) para mi cabina de discos y este es el resultado:

En este caso nos fijamos en el último dispositivo, que es el que no está dando unos valores anómalos. Como se puede apreciar, la SAN es una HITACHI.

Por otro lado, ahora nos fijamos en el segundo contador, (Physical device command latency). Este valor, en principio, nos tiene que venir dado por el fabricante de la cabina, en mi caso HITACHI, pero yo no lo he conseguido. Me voy a basar en los estándares.
En este caso tenemos que los siguientes discos:
-
t10.HITACHI_770501211902.- Este disco está por encima de los 20 milisegundos.
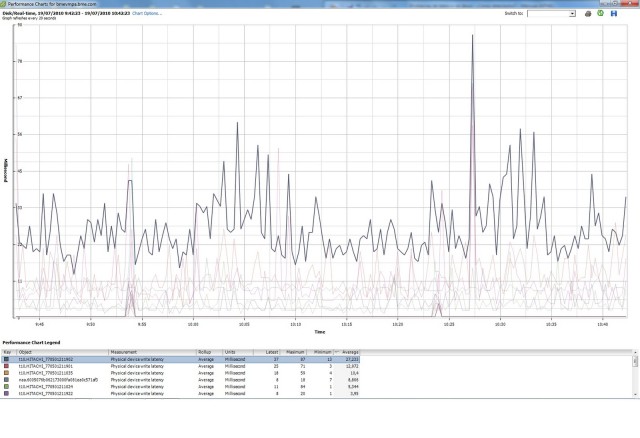
-
t10.HITACHI_770501211901.- Este disco ronda los 11 milisegundos en media con ligeros picos por encima de los 20 milisegundos.


¿Cómo seguir desde aquí? Bien, sabemos qué maquinas componen la citada LUN, en mi caso contiene las siguientes Máquinas Virtuales (VM):
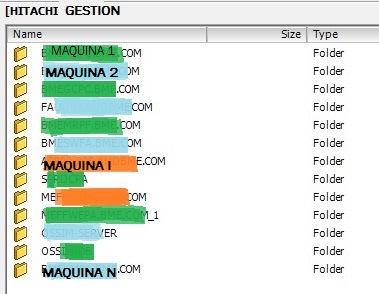
Habría que ir moviendo una a una cada VM a otra LUN y verificar cuál es la que está provocando este fallo.
El próximo día Iperf en modo gráfico.
Un saludo,