>
Hola.
De imprescindible lectura para comprender el desarrollo de esta entrada son los artículos de David que enumero a continuación:
http://blogs.technet.com/davidcervigon/archive/2008/12/17/sobre-clusters-de-hyper-v-y-clusteres-virtuales.aspx
http://blogs.technet.com/davidcervigon/archive/2010/02/01/consideraciones-sobre-los-cluster-shared-volumes-csv.aspx
http://blogs.technet.com/davidcervigon/archive/2009/04/17/cl-steres-virtuales-guest-clustering.aspx
Una vez leído sobre todo el primer artículo, extraigo lo siguiente:
“Para ellos, cada CSV tiene un nodo designado como “coordinador”, y el, y solo el, es el encargado de gestionar el espacio de nombres del volumen, y la creación de nuevos ficheros. Sin embargo, existe un filter driver en cada nodo que es capaz de distinguir el I/O producido por estos accesos y operaciones “del explorador de Windows”, para entendernos, del derivado de las lecturas/escrituras rápidas sobre un fichero (en este caso los VHDs) que requiere Hyper-V para trabajar de manera eficiente. El primero es redirigido al coordinador del CSV a través de la red configurada con menor métrica en el cluster (generalmente la interna, o de heartbeat)”
A toda la teoría aparecida, hay que añadir que en el caso de que un nodo pierda el acceso a disco de todas las formas posibles, desconexión física del servidor a la cabina, mala configuración en el conector iscsi, no asignación de permisos adecuados en la cabina a un nodo del clúster, más todas los posibles problemas similares y alguno más que un simple “hobbit” descubrirá seguro, el nodo que se queda sin acceso a la lun CSV, verá esta a través del servidor propieatario de la lun y designado como servidor de transacciones, con lo que venimos a explicar es que para perder el acceso y que nos veamos en un problema grave, no solo el servidor que levanta una máquina virtual ha perder conectividad con la cabina, si no que además debe de perder conectividad por (normalmente) la tarjeta de hearbeath.
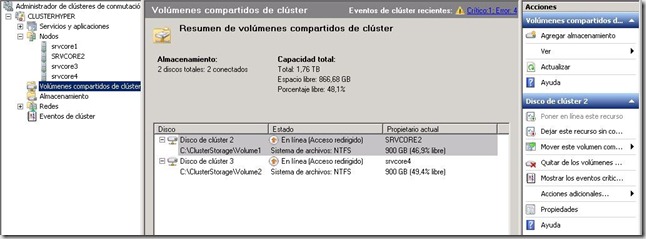
Problema
Al final de esto, si perdemos conectividad con la cabina, desde cualquier de los nodos del cluster, lo veamos desde donde lo veamos, los CSV aparecerán tal que así (Fijaros en el color amarillo y en texto “Acceso redirigido” que aparece en cada CSv):
¿Solución?
Pues encontrar el nodo que no tiene un acceso correcto a la cabina, en mi caso estaba provocado al tener quitados todos los accesos iscsi.
Una vez restablecidos estos a través además de doble camino (estoy con el tercero y el cuarto).
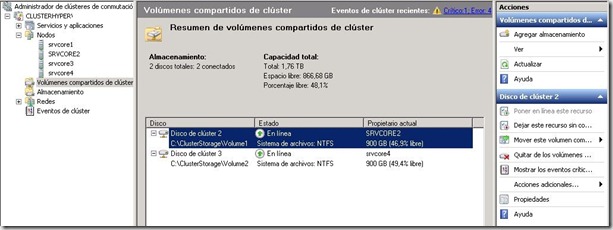
Y cuando todos los servidores tienen on-line las luns, todo aparece OK y en verde:
Nota: Podría haber hecho todas estas operaciones, teniendo el servidor en producción y con las máquinas virtuales que salen por él encendidas, sin embargo, como podéis imaginar, este servidor había sido liberado de máquinas virtuales unos momentos antes, gracias a Live y Quick Migration.
Además he provocado la aparición de “Acceso Redirigido” dejando el nodo como funcional en el cluster, bien hecho (y es como he hecho la operación en producción), habría que dejar el servidor con el servicio de clúster detenido.
Saludos.




