
Exchange 2013: Disponibilidad y fiabilidad (conclusiones)
Siguiendo el post anterior sobre Exchange 2013: Disponibilidad y fiabilidad (Conceptos) esta segunda parte trata de reconocer el la forma de entender los dominios de fallo para entender que se puede redundar.
Dominios de fallo
En lo que hemos visto hasta ahora es relevante reconocer que estamos hablando de que uno u otro componente, este o aquel, es el que puede fallar. Eso se corresponde con un dominio de fallo. El fallo o error en un dominio rompe la independencia o la redundancia de los componentes que combina. Por ejemplo, el fallo de hardware de servidor en un servidor con varios roles significa que todas las funciones de Exchange en este servidor dejan de estar disponibles; en consecuencia, el fracaso de un contenedor de discos o una matriz SAN significa que todas las copias de bases de datos alojados en esta matriz no estarán disponibles.
Supongamos dos escenarios:
1. Todo esta en un servidor, varios roles. CAS+MBx
2. Los roles se reparten entre dos servidores. CAS y MBx separados
En el primer caso, o esta disponible el servidor o no lo está. Siguiendo el anterior post,
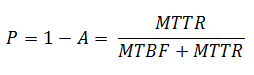
En el segundo caso, tienen que estar los dos servidores disponibles para poder dar servicio y por la ley de la probabilidad, A × A = A2.
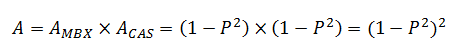
A<1, A2 < A
Porque el problema es que los sistemas dependientes lo son por que ser independientes ellos mismos. Si fallan, los dependientes fallan aunque este funcionando, por eso tomamos cada elemento como parte independiente y dependiente a la vez. Poniendo varios roles en el mismo servidor evitamos sistemas intermedios que hacen menos disponibles todo el sistema.
Segunda cuestión: almacenamiento
Ahora consideremos otro escenario de dominio de fallo (dos copias de bases de datos que comparten la misma matriz de almacenamiento), y comparamos la disponibilidad de bases de datos en los dos casos siguientes:
1. Dos copias de bases de datos alojados en el mismo almacenamiento compartido (matriz SAN o espacio DAS), que tiene la probabilidad de fallo de P;
2.Las mismas copias de bases de datos hospedadas en dos sistemas de almacenamiento separados, cada uno tiene la misma probabilidad de fallo;
En el primer caso, almacenamiento compartido representa un dominio de fallo.
Al igual que en el escenario anterior, esto significa que ambas copias de bases de datos están disponibles o no disponibles de forma simultánea, por lo que la disponibilidad general es de nuevo A = 1 – p
En el segundo caso, el servicio en general estará disponible si al menos un sistema está disponible, y no estará disponible sólo si ambos sistemas fallan. Los sistemas de almacenamiento en cuestión son independientes; Por lo tanto, la probabilidad de fallo para el servicio en general es P × P = P2, y la disponibilidad global del servicio correspondiente es A = 1 – P2.
Una vez más, como P <1, significa que P2 <P, y por lo tanto 1 – P2> 1 – P. Esto significa que la disponibilidad en el segundo caso es más alta. Poner las de bases de datos en el mismo sistema de almacenamiento disminuye la disponibilidad general del servicio.
Por tanto, se trata de establecer la relación entre roles compartidos en el servidor, por sus dependencias si fueran distribuidos, por ser dominios de fallo independientes, y la relación entre redundancia de componentes que pertenecen al mismo dominio de fallo.
Con ello, de forma más o menos grafica, queremos explicar que la Disponibilidad va a depender de establecer con claridad los únicos puntos de fallo, dominios, y reconocer su redundancia.
El siguiente post tratará ese diseño posible.